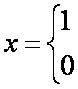
MODEL EKONOMETRYCZNY A ZMIENNE ZERO-JEDYNKOWEEkonometriaStrona główna | Ekonometria | Statystyka | Prognozowanie i symulacje | Formularz kontaktowy
|
Pojęcie model ekonometryczny definiowane jest różnie. Pod tym pojęciem należy rozumie funkcję y zmiennych objaśniających i składnika losowego o postaci analitycznej f:
y = f (X, α, ξ),
której parametry wyznacza się na podstawie materiału statystycznego opisującego kształtowanie się zmiennej objaśnianej i zmiennych objaśniających.
Zmienne objaśniane stanowią charakterystyki badanych zjawisk, których mechanizmy zmian chcemy poznać, a zmienne objaśniające opisują czynniki (zjawiska), które na nie wpływają; może wystąpić wśród nich zmienna czasowa.
1. Jakościowe zmienne objaśniające:
Występujące w modelach ekonometrycznych zmienne są zmiennymi ilościowymi przyjmującymi teoretycznie nieskończenie wiele wartości. Jednak znaczna część zjawisk ekonomicznych i społecznych ma charakter jakościowy, co w związku z tym ogranicza liczbę stanów, jakie mogą przyjmować.
Najczęściej ich reprezentantami w modelu są zmienne zero - jedynkowe, które przyjmują tylko dwie wartości, są to więc zmienne dychotomiczne. Dychotomiczna zmienna w modelu przyjmuje wartości:
1- jeżeli zdarzenie wystąpi ( obiekt ma daną cechę );
2- jeżeli zdarzenie nie wystąpi ( obiekt nie ma danej cechy )
Zmienne te w tym modelu mogą pełnić rolę zarówno zmiennych objaśniających, jak i objaśnianych.
W modelu ekonometrycznym na badaną zmienną często wpływ wywierają np. miejsce zamieszkania badanej osoby, płeć pracownika, itp.
Reprezentujące je zmienne objaśniające wprowadza się do modelu jako zmienne zero - jedynkowe przypisując im wartość zero bądź jeden, zależnie od występującej sytuacji.
Traktuje się więc je tak jak zmienne ilościowe, a oceny ai stojących przy nich parametrów uzyskiwane są KMNK.
2. Zero - jedynkowe zmienne objaśniane:
Sytuacja się komplikuje, gdy model ekonometryczny budowany jest w celu wyjaśnienia zjawisk opisywanych przez zmienną jakościową. Tak na przykład: rodzina może nabyć mieszkanie lub nie, czy też np. osoba może spędzić urlop za granicą lub w kraju. Wybór odpowiedniego wariantu przez każdą z rodzin ( bądź osób ) zależy od różnych czynników, z których najważniejsze traktujemy jako zmienne objaśniające, jak np. zamożność rodziny, wiek jej członków, itp. W takich przypadkach zarówno budowa modelu, jak i estymacja jego parametrów KMNK jest utrudniona w porównaniu z sytuacją, gdy w modelu zmienne jakościowe występują w roli objaśniających.
Przyjmijmy, że interesujący nas model, który wyjaśnia gdzie badana osoba spędzi urlop. Zmienna objaśniana ( Y ) jest zmienną zero – jedynkową przyjmującą wartość jeden, gdy osoba spędza urlop w kraju, a zero – w przeciwnym wypadku. Ponadto załóżmy,że jedyną zmienną objaśniającą ( X ) jest dochów przypadający na osobę. Interesujący nas model będzie mieć postać:
yj = α0 + α1xj + ξj ; (1)
gdzie j jest numerem badanej jednostki.
Na podstawie obserwacji n osób otrzymamy więc model:
ŷj = α0 + α1xj , j=1,...,n, (2)
gdzie:
ŷj – realizacja zmiennej losowej Y =1, jeżeli j - ta osoba spędziła urlop w kraju, a Y =0 jeżeli spędziła urlop poza krajem;
xj – wysokość dochodów ( w zł/osobę ) przypadająca na j-tą osobę.
W powyższym modelu wartość oczekiwana zmiennej objaśnianej może być interpretowana jako warunkowe prawdopodobieństwo realizacji danego zdarzenia przy ustalonych wartościach zmiennej objaśniającej. Wartość ŷ jest uważana za oszacowanie tego prawdopodobieństwa. Jednak w ogólnym przypadku wyrażenie (2) będące liniową funkcją dochodu może przyjąć wartość spoza przedziału [0,1]. Inną niedogodnością w stosowaniu tego modelu jest heteroscedastyczność składnika losowego, co uprawnia do szacowania jego parametrów za pomocą KMNK.
W celu
uniknięcia większych od jedności czy też ujemnych wartości prawdopodobieństwa
dokonuje się monotonicznego przekształcenia prawdopodobieństwa z przedziału
(0,1) na przedział
![]() .
Dla prawdopodobeństwa rosnącego od zera do jedności jego przekształcenie wzrasta
od
.
Dla prawdopodobeństwa rosnącego od zera do jedności jego przekształcenie wzrasta
od
![]() do
do
![]() .
.
W ten sposób unika się skończonego przedziału dla zmiennej objaśnianej. Istnieje dużo przekształceń o tej właściwości, z których najpopularniejsze są dwa :
- przekształcenie probitowe
- przekształcenie logitowe
Skorzystanie z tego przekształcenia wymaga wprowadzenia pewnej liczby kategorii
zmiennej objaśniającej, tak aby można było mierzyć częstość p wystąpienia
wariantu zmiennej objaśnianej w każdej z tych kategorii. Konieczność
posługiwania się częstościami wynika z faktu, że zmienna zero – jedynkowa
przyjmuje tylko dwie wartości: 0 i ![]() i
i
![]() .
.
Transformacja probitowa polega na przekształceniu danego prawdopodobieństwa ( częstości ) p na wartość dystrybuanty F standaryzowanego rozkładu normalnego. Przekształcenie to wywodzi się z nauk biologicznych.
Np. jeżeli w rozważanym modelu p(x) oznaczać będzie prawdopodobieństwo spędzenia urlopu w kraju przez osobę o dochodzie nie przekraczającym X, to przekształcenie probitowe będzie miało następującą postać:
![]()
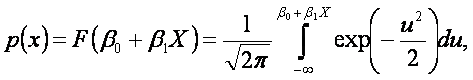 (3)
(3)
przy czym zmienna losowa U ma rozkład N (0,1).
Równoważnie przekształcenie to można wyrazić następująco:
![]() (4)
(4)
gdzie F -1 jest funkcją odwrotną do dystrybuanty standaryzowanego rozkładu normalnego.
F –1[p(x)] jest probitem i będzie oznaczane symbolem P. Aby uniknąć wartości ujemnych, wartość otrzymaną z powyższego przekształcenia powiększa się o liczbę 5. Niech np. przyjęta za prawdopodobieństwo częstość wystąpienia badanego zdarzenia wynosi 0,20, czyli dystrybuanta standaryzowanego rozkładu normalnego N(0,1) F(u) = 0,20 i z tablic tej dystrybuanty mamy u = -0,84. Wartość probitu wyniesie więc P = -0,84+5=4,16.
Tabela 1.
Przekształcenia prawdopodobieństw na probity
|
Prawdo- podobień- stwo |
0,01 |
0,02 |
0,03 |
0,04 |
0,05 |
0,06 |
0,07 |
0,08 |
0,09 |
|
|
0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 |
- 3,72 4,16 4,48 4,75 5,00 5,25 5,52 5,84 6,28 |
2,67 3,77 4,19 4,50 4,77 5,03 5,28 5,55 5,88 6,34 |
2,95 3,82 4,23 4,53 4,80 5,05 5,31 5,58 5,92 6,41 |
3,12 3,87 4,26 4,56 4,82 5,08 5,33 5,61 5,95 6,48 |
3,25 3,92 4,29 4,59 4,85 5,10 5,36 5,64 5,99 6,55 |
3,36 3,96 4,33 4,61 4,87 5,13 5,39 5,67 6,04 6,64 |
3,45 4,01 4,36 4,64 4,90 5,15 5,41 5,71 6,08 6,75 |
3,52 4,05 4,39 4,67 4,92 5,18 5,44 5,74 6,13 6,88 |
3,59 4,08 4,42 4,69 4,95 5,20 5,47 5,77 6,18 7,05 |
3,66 4,12 4,45 4,72 7,497 5,23 5,50 5,81 6,23 7,33 |
|
- |
0,000 |
0,001 |
0,002 |
0,003 |
0,004 |
0,005 |
0,006 |
0,007 |
0,008 |
0,009 |
|
0,99 |
7,33 |
7,37 |
7,41 |
7,46 |
7,51 |
7,58 |
7,65 |
7,75 |
7,88 |
8,09 |
Po zastąpieniu prawdopodobieństw ( częstości ) probitami model (1) przybierze następującą postać:
![]() (5)
(5)
Transformacja
logitowa z kolei wykorzystuje zmiany prawdopodobieństwa z przedziału (0,1)
na przedział
![]() ,
czyli tzw. logity:
,
czyli tzw. logity:
 (6)
(6)
których wartość wynosi
![]() dla
p = 0, zero dla p = 0,5 oraz
dla
p = 0, zero dla p = 0,5 oraz
![]() dla
p = 1. Dla innych wielkości p wartości logitów zawrte są w
poniższej tabeli
dla
p = 1. Dla innych wielkości p wartości logitów zawrte są w
poniższej tabeli
|
Prawdo- podobień- stwo |
0,01 |
0,02 |
0,03 |
0,04 |
0,05 |
0,06 |
0,07 |
0,08 |
0,09 |
|
|
0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 |
-4,60 -2,09 -1,33 -0,80 -0,36 0,04 0,45 0,90 1,45 2,31 |
-3,89 -1,99 -1,27 -0,75 -0,32 0,08 0,49 0,94 1,52 2,44 |
-3,48 -1,90 -1,21 -0,71 -0,028 0,12 0,53 1,00 1,59 2,59 |
-3,18 -1,82 -1,15 -0,66 -0,24 0,16 0,58 1,05 1,66 2,75 |
-2,94 -1,74 -1,10 -0,62 -0,20 0,20 0,62 1,10 1,74 2,94 |
-2,75 -1,66 -1,05 -0,58 -0,16 0,24 0,66 1,15 1,82 3,18 |
-2,59 -1,59 -1,00 -0,53 -0,12 0,28 0,71 1,21 1,90 3,48 |
-2,44 -1,52 -0,94 -0,49 -0,08 0,32 0,75 1,27 1,99 3,89 |
-2,31 -1,45 -0,90 -0,45 -0,04 0,36 0,80 1,33 2,09 4,60 |
|
|
- |
0,000 |
0,001 |
0,002 |
0,003 |
0,004 |
0,005 |
0,006 |
0,007 |
0,008 |
0,009 |
|
0,99 |
4,60 |
4,70 |
4,82 |
4,96 |
5,11 |
5,29 |
5,52 |
5,81 |
6,21 |
6,91 |
![]() (7)
(7)
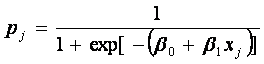 (8)
(8)
Modele ze zmiennymi zero-jedynkowymi.
Opierając się na przykładzie makrofunkcji
konsumpcji dla Stanów Zjednoczonych zakładamy, że próba statystyczna obejmuje
lata 1940-
Może to oznaczać konieczność uzmienniena w rozważanej funkcji:
wyrazu wolnego
współczynnika kierunkowego
wyrazu wolnego
współczynnika kierunkowego, czyli tzw. segmentacji próby.
Przedstawiona analiza dotyczy modelu z jedną zmienną objaśniająca choć
rozszerzenie jej na funkcje wielu zmiennych nieprzedstawia żadnych trudności.
(1) Zmiana wyrazu wolnego
Zgodnie z hipotezą ekonomiczną zakłada się w tym przypadku, ze wojna
spowodowała obniżenie poziomu konsumpcji (np. na skutek racjonowania), lecz
zmianie nie uległa krańcowa skłonność do konsumpcji.
Odpowiedni model można zapisać następująco:
![]() dla t = 1940, 1941, 1946,...,1950 (9)
dla t = 1940, 1941, 1946,...,1950 (9)
![]() dla
t = 1942,..., 1945 (10)
dla
t = 1942,..., 1945 (10)
lub w zwartej postaci:
![]() (11)
(11)
gdzie Ut jest zmienną przyjmującą wartość zero w okresie pokoju i pewną wartość rzeczywista a w pozostałych latach:
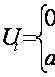
dla t = 1940, 1941, 1946,..., 1950
dla t = 1942, 1943, 1944, 1945
Dane dotyczące gospodarki USA, stąd też okres II wojny światowej obejmuje lata po
przystąpieniu USA do wojny.Ze względów interpretacyjnych. wygodnie jest jednakże, aby wartość a była tożsamościowo równa jedności Wówczas wektor U(t) będzie złożony z ciągów zer i jedynek. Jest to powód, dla którego zmienne tego typu nazywane zmiennymi zero-jedynkowymi (ang. dummy variables lub binary variables).
Dalsze postępowanie jest tradycyjne: należy oszacować parametry modelu
(11) na podstawie pełnej próby statystycznej tj.. 1940-1950), np. za pomocą
metody najmniejszych kwadratów. Wartość
![]() poszukiwaną
informacje, o ile średnio obniżyła się konsumpcja w okresie wojny.
Sprawdzenie, czy oszacowana zmiana jest statystycznie istotna, sprowadza się do
testowania hipotezy
poszukiwaną
informacje, o ile średnio obniżyła się konsumpcja w okresie wojny.
Sprawdzenie, czy oszacowana zmiana jest statystycznie istotna, sprowadza się do
testowania hipotezy
o istotności parametru
![]() .
.
(2) Zmiana współczynnika kierunkowego
Formułując wyjściową hipotezę zakłada się tutaj, ze na skutek wojny spadła
krańcowa skłonność do konsumpcji, czemu odpowiada następujący model:
![]() (12)
(12)
lub równoważne:
![]() (13)
(13)
gdzie:
dla t = 1940, 1941, 1946,..., 1950![]()
dla t = 1942, 1943, 1944, 1945
Testując istotność parametru
![]() można
stwierdzić czy dane statystyczne pozwalają na wysuniecie takiej hipotezy.
Otrzymana w wyniku estymacji modelu (13), ocena parametru
można
stwierdzić czy dane statystyczne pozwalają na wysuniecie takiej hipotezy.
Otrzymana w wyniku estymacji modelu (13), ocena parametru
![]() informuje
o różnicy między skłonnością do konsumpcji w czasie wojny i pokoju.
informuje
o różnicy między skłonnością do konsumpcji w czasie wojny i pokoju.
Oszacowanie tej ostatniej dla okresu wojny wynosi natomiast, zgodnie ze wzorem (12),
![]()
Wyrażenie UtYt często jest nazywane zmienna interakcyjna (ang. interactive variable).
(3) Zmiana wyrazu wolnego i współczynnika kierunkowego.
W tym przypadku, struktura modelu
musi umożliwić korektę obydwu parametrów
![]() i
i
![]() jednocześnie:
jednocześnie:
![]() (14)
(14)
Estymacja parametrów powyższego
równania metoda najmniejszych kwadratów, przyniesie numerycznie taki sam
rezultat, jak dwukrotna estymacja modelu postaci (9) i (10) na
podstawie dwóch rozłącznych prób, tj. okresu wojny i pokoju. Różnica dotyczy
wszakże estymatora wariancji składnika losowego,
![]() który
w tym drugim przypadku utraci efektywność. Wynika to z faktu, że wyjściowy
model (14).
który
w tym drugim przypadku utraci efektywność. Wynika to z faktu, że wyjściowy
model (14).
Zmiana wyrazu wolnego i współczynnika kierunkowego
zakłada stałość wariancji w całym
okresie 1940-1950, estymując zaś
![]() jedynie
na
podstawie części obserwacji, nie
wykorzystuje się informacji zawartych w pominiętej podpróbie.
jedynie
na
podstawie części obserwacji, nie
wykorzystuje się informacji zawartych w pominiętej podpróbie.
Możliwe jest także wysuniecie bardziej skomplikowanej hipotezy, iż poszczególne lata wojny były tak różne, ze z okresu na okres następowała wówczas zmiana poziomu konsumpcji. Zamiast jednej zmiennej. specyfikacje modelu należy zatem
rozszerzyć o cztery zmienne zero-jedynkowe, przyjmujące wartość jeden kolejno w latach 1942, 1943, 1944 i 1945, zero zaś w pozostałach.
Na przykład, równanie analogiczne do (14) miałoby wówczas postać:
![]() (15)
(15)
gdzie:
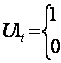
dla t = 1942
w pozostałych latach
![]()
dla t = 1943
w pozostałych latach
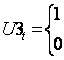
dla t =1944
w pozostałych latach
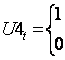
dla t = 1945
w pozostałych latach
Takie postępowanie jest jednak równoważne usunięciu lat wojny ze zbioru obserwacji .
Jednoczesne zastosowanie kilku zmiennych zero-jedynkowych jest często spotykane w modelach opartych na danych kwartalnych (miesięcznych), co wiąże się z tym, iż dane takie wykazują zwykle cykliczne wahania sezonowe. Efekty są szczególnie dobrze widoczne w przypadku konsumpcji, zwłaszcza jeśli posługujemy sie informacjami dotyczącymi wybranych grup towarów. Odpowiedni model. zakładający kwartalne zróżnicowanie poziomu konsumpcji. jest następujący:
![]() (16)
(16)
gdzie:
![]()
![]()
dla II kwartału
w pozostałych latach
dla III kwartału
w pozostałych latach
![]() dla IV kwartału
dla IV kwartału
w pozostałych latach
Parametry ![]() ,
,![]() ,
,![]() mierzą
różnice poziomu konsumpcji, odpowiednio
mierzą
różnice poziomu konsumpcji, odpowiednio
w drugim, trzecim i czwartym kwartale, względem pierwszego kwartału .
Macierz obserwacji modelu (16) jest następująca:
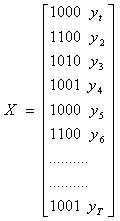 (17)
(17)
Rozszerzenie specyfikacji (16) o czwartą zmienną zero-jedynkową U1,
przyjmującą wartość jeden w pierwszym kwartale. wprowadziłoby współliniowość,
bowiem: U1t+U2t+U3t+U4t=1. Jeśli jednak z jakichś powodów wygodnie jest
szacować średni absolutny poziom badanego zjawiska w poszczególnych kwartałach, to, uwzględniając wszystkie cztery zmienne zero-jedynkowe. Należy pominąć w funkcji (16) wyraz wolny:
![]() (18)
(18)
gdzie:
![]()
dla I kwartału
dla pozostałych
Zastosowanie zmiennych zero-jedynkowych stanowi najprostszy sposób ,,usunięcia” sezonowości obecnej w danych (ang. deseasonalising the data).
Odpowiedz na pytanie, czy efekty sezonowości są istotne statystycznie, polega na weryfikacji zespołu hipotez:
![]()
![]()
którego sprawdzianem jest statystyka F.
Niekiedy wiedza a priori dotycząca badanych zjawisk, pozwala wysunąć
hipotezę, ze obniżenie poziomu zmiennej objaśnianej w okresie to nie będące
skutkiem oddziaływania zmiennych objaśniających, zostało w całości skompensowane przez jej wzrost w następnym okresie, tl. (por. rysunek 6,2), Sytuacje takie mają czasami miejsce, w przypadku niektórych zmiennych finansowych (np. podatków, ceł. których zmiany są nierzadko wynikiem egzogenicznych decyzji administracyjnych. Wówczas zdefiniowane zmiennej Ut w sposób następujący:
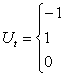
dla t = t0
dla t = t1
dla pozostałych okresów
i wprowadzenie jej addytywne do modelu:
![]() (19)
(19)
pozwala uwzględnić posiadane informacje.
Rysunek 6.2. Kompensacyjne zmiany zmiennej objaśnianej
Nietrudno wyobrazić sobie bardziej skomplikowane postacie tego typu zmiennych sztucznych, które mogą również modyfikować wybrany współczynnik kierunkowy funkcji (19).
Korekta parametru powinna jednakże czasami mieć charakter ewolucyjny gładki, nie zaś skokowy.
Przykładem modelu realizującego ten postulat jest równanie:
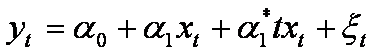 (20)
(20)
gdzie t reprezentuje trend ( zmienna czasową ).
Weryfikacja zespołu hipotez:
![]()
![]()
którego sprawdzianem jest statystyka o rozkładzie t - studenta:
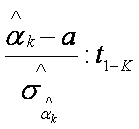
jest najprostszym sposobem zbadania zasadności wyjściowego założenia.
Naturalne uogólnienie powyższego modelu polega na wprowadzeniu w miejsce zmiennej czasowej t funkcji trendu, f ( t ):
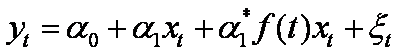
Funkcja f ( t ) może być dodatkowo tak określana aby przyjmować wartości niezerowe tylko w pewnym przedziale, co zbliża ją charakterem do zmiennych sztucznych.
Zmienne sztuczne, w tym także zero-jedynkowe, są ważnym – choć często nadużywanym narzędziem w analizie regresji. Ich zastosowanie powinno zawsze wynikać z poważnych przesłanek ekonomicznych, tak jak ma to miejsce w przypadku jakiejkolwiek innej zmiennej, wykorzystywanej w charakterze regresowa.
Mapa strony ekonometria.4me.pl
![]()
Copyright © ekonometria.4me.pl 2005-2013. Wszelkie prawa zastrzeżone. Zabrania się kopiowania, redystrybucji, publikacji lub modyfikacji jakichkolwiek materiałów zawartych na stronie internetowej , bez wcześniejszej pisemnej zgody autorów.
MODEL EKONOMETRYCZNY A ZMIENNE ZERO-JEDYNKOWE